In this project, I’ve built a Scraper/Bot to get equipment data from testmart.com using Scrapy Web Crawling Framework.
Problem
The client needs data from thousands of equipment of National Instruments corporation type from testmart.com to perfom data analysis.
Task
Create an automated and fast solution to navigate the website, extract all the data of the National Instruments corporation type, and save it in a user-friendly format (CSV, JSON and XML).
Solution
I’ve used the Scrapy Web Crawling Framework to build a Python script to scrape (extract) the data of all equipment found in the National Instruments corporation type.
Results
The client was able to quickly download the data of almost 50,000 equipments from testmart.com.
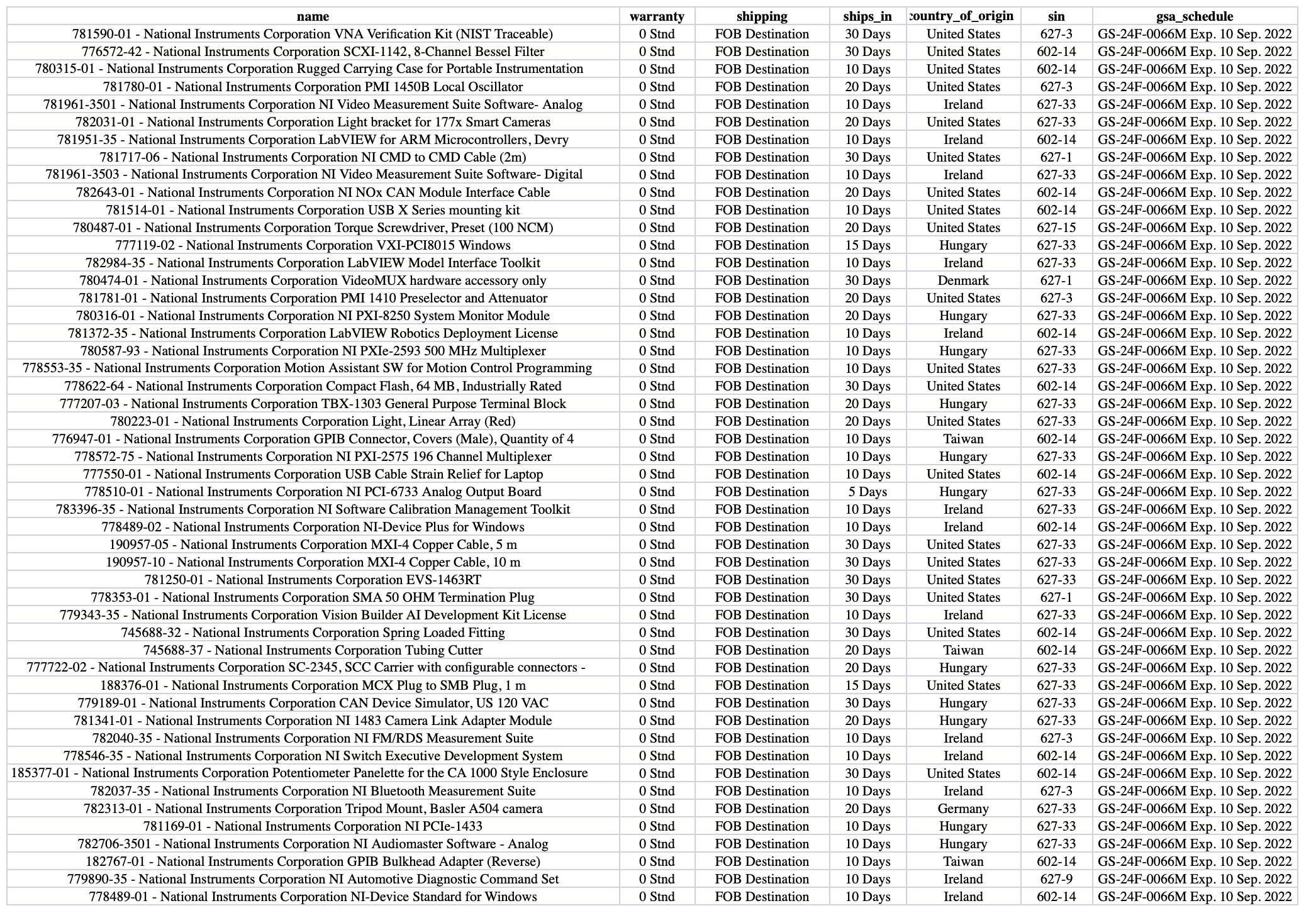
The data was used for data analysis and add great value to the client business.
Source code
The solution is available at Github.

How to use
You will need Python 3.5+ to run the scripts. Python can be downloaded here.
You have to install the Scrapy framework and other required packages:
- In command prompt/Terminal:
pip install -r requirements.txt
Once you have installed Scrapy framework, just clone/download this project:
git clone https://github.com/cpatrickalves/scraping-gsamart.git
Access the folder in command prompt/Terminal and run the following command:
scrapy crawl gsamart_nic -o equipaments.csv
You can change the output format to JSON or XML by change the output file extension (ex: equipaments.json).